Google Indexierung: So indexierst Du Deine Website richtig
09.09.2021 | Sophie Garban | SEO
Teile diesen Beitrag
Die Steuerung der Indexierung ist nach wie vor eine enorm wichtige Aufgabe in der Suchmaschinenoptimierung (SEO). Das Ziel hierbei ist, nur erwünschte Seiten von Google indexieren zu lassen und dabei Duplikate zu vermeiden. Es existieren verschiedene technische Werkzeuge, mit welchen Du die Seiten im Google Index steuern kannst. Werden diese Werkzeuge allerdings miteinander verwechselt oder falsch eingesetzt, kann das dazu führen, dass die gewollte Wirkung verloren geht oder sogar negative Signale an die Suchmaschine gesendet werden. In diesem Artikel zeigen wir Dir, welche Werkzeuge existieren und für welche Fälle diese eingesetzt werden.
Indexierung im SEO – Inhaltsverzeichnis:
Warum ist die Steuerung der Indexierung wichtig?
Wie überprüfe ich die aktuell indexierten Seiten?
Wie kann die Indexierung beeinflusst und Duplikate vermieden werden?
robots.txt
Meta-Tag Robots
Canonical Tags
Kombinationen von diesen Werkzeugen
Fazit
Warum ist die Steuerung der Indexierung wichtig?
Hier geht es in erster Linie darum, dem User und der Suchmaschine nur Seiten, welche einen Mehrwert bieten, zur Verfügung zu stellen. Bei Domains sammeln sich aber im Laufe der Zeit immer wieder Seiten ohne Inhalt oder Duplikate an, welche keine Relevanz für den User haben.
Von Duplikaten spricht man vereinfacht gesagt, wenn mehrere inhaltlich sehr ähnliche oder exakt gleiche Seiten mit unterschiedlichen URLs existieren. Das erschwert dem Googlebot das Crawling und die Bewertung der Seiten und kann zu einem schlechteren Ranking bzw. einem unerwünschten Ranking des Duplikats anstatt der gewünschten Originalseite führen.
Gleichzeitig gibt es Seiten oder sogar ganze Bereich auf der Domain, welche zwar keine Duplikate darstellen, aber dennoch nicht im Index und damit in den Suchanfragen erscheinen sollen. Beispiele hierfür können Seiten im Zahlungsprozess, Serviceseiten oder auch Verzeichnisse mit Bildern sein.
Wie überprüfe ich die aktuell indexierten Seiten?
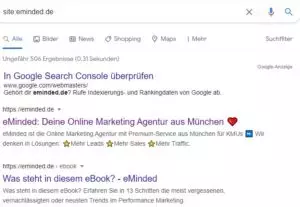
Um die aktuell indexierten Seiten zu überprüfen und um mögliche Problematiken zu identifizieren, kann die sogenannte Site-Abfrage der Google Search verwendet werden. Um eine Site-Abfrage durchzuführen, musst Du Folgendes in die Google-Suche eingeben: „site:www.eure-domain.de“
Als Suchergebnisse bekommst Du nun alle URLs angezeigt, welche sich im Index befinden. Solltest Du mehrere Subdomains haben, dann gib die Domain ohne www. ein, um alle Seiten angezeigt zu bekommen. Achte bei den Ergebnissen neben den Inhalten der Snippets auch auf URLs mit Parametern und/oder auf Ergebnisse, welche für Dich keinen Sinn ergeben. Natürlich kann bei mehreren Tausend indexierten Seiten nicht jede einzelne überprüft werden. Aber Du solltest durch eine erste Analyse einen groben Eindruck von der Qualität der indexierten Seiten erhalten und auch Muster bei möglichen Problemen feststellen können.
Wie kann die Indexierung beeinflusst und Duplikate vermieden werden?
Nun möchten wir die Frage klären, wie die Handhabung bei existierenden Seiten erfolgt. Um das Crawling bzw. die Indexierung zu steuern, werden die folgenden Werkzeuge verwendet:
Robots.txt
Meta-Tag Robots
Canonical Tags
Es gibt neben diesen Punkten natürlich noch andere Mittel, um die Indexierung von Seiten Deiner Website kurz- oder langfristig aufzuheben, wie zum Beispiel den Statuscode 410 oder auch Weiterleitungen. Diese beiden Punkte werden aber bei Seiten angewendet, welche nicht mehr existieren, und sollen daher zunächst nicht besprochen werden.
Robots.txt
Aufbau der robots.txt
Nach der Übereinkunft des Robots-Exclusion-Standard-Protokolls liest ein Webcrawler (Robot) beim Auffinden einer Webseite zuerst die Datei robots.txt (kleingeschrieben) im Stammverzeichnis („root“) einer Domain. In dieser Datei kann festgelegt werden, ob und wie die Webseite von einem Webcrawler besucht werden darf. Website-Betreiber haben so die Möglichkeit, ausgesuchte Bereiche ihrer Webpräsenz für (bestimmte) Suchmaschinen zu sperren.
Durch diese Datei sagt Ihr also Google, welche Seiten besucht werden können und welche Seiten nicht besucht werden dürfen. Eine Grundstruktur könnte beispielsweise so aussehen:
Mit diesem Eintrag in der Robots.txt erlaubst Du den Suchmaschinen (User-Agent) bis auf die beiden ausgeschlossenen Verzeichnisse alle Seiten zu besuchen. Außerdem wird auch der Pfad der Sitemap angezeigt, was den Suchmaschinen ein schnelleres Verständnis der Websitearchitektur ermöglicht.
Es muss hier allerdings erwähnt werden, dass ein Ausschluss bestimmter Seiten oder Verzeichnisse in der robots.txt nicht die grundsätzliche Indexierung und somit das Erscheinen in den Suchergebnissen verhindert. Jedoch halten sich heute die meisten Suchmaschinen an die Angabe in der Datei.
Tipp: Reiche die Sitemap auch in der Search Console ein.
Verwendung der robots.txt
Ein Eintrag in der robots.txt eignet sich hervorragend, um komplette Seitenbereiche bzw. Verzeichnisse vom Crawling auszuschließen. Hier solltest Du aber Vorsicht walten lassen und dennoch den Ausschluss nicht zu breit vornehmen. Solltest Du gleichzeitig Google Ads schalten, muss sichergestellt werden, dass zumindest der Ads-Crawler eine Ausnahme erhält.
Meta-Tag Robots
Aufbau und Variationen der Meta-Tags
Der oben genannte Meta-Tag dient dazu, das Verhalten des Crawlers bzw. Google Bots (sowie der anderen Web-Crawler) zu steuern. Es existieren hierbei vier Werte, die auch miteinander kombiniert werden können:
• „index“: Seite wird indexiert • „noindex“: Seite wird nicht indexiert • „follow“: Den Links auf der betreffenden Seite folgen • „nofollow“: Den Links auf der betreffenden Seite nicht folgen
Wird auf einer Website das Tag nicht gesetzt, so wird die betreffende Seite durch den Crawler indexiert und allen Links wird gefolgt. Das entspricht daher diesem Tag:
<meta name=“robots“ content=“index, follow“>
Soll nun eine Seite nicht indexiert, aber den Links gefolgt werden kommt das folgende Tag zum Einsatz:
<meta name=“robots“ content=“noindex, follow“>
Verwendung der Meta Tags
Dieses Tag ist eine sehr strikte Anweisung an Google und kann daher auf allen Seiten, welche nicht in den Index gehören angewendet werden. Beispiele hierfür sind:
Ergebnisse der internen Suche
Paginierte Seiten
Canonical-Tag
Aufbau des Canonical Tags
Beim Setzen des Canonical-Tags ist es möglich, dem Google-Bot eine bevorzugte Seite (kanonische Seite) bei mehreren Seiten mit sehr ähnlichen bzw. gleichem Inhalt mitzuteilen. Diese Methode wird häufig bei Filterseiten verwendet. Generell empfiehlt es sich das Canonical-Tag auf allen Seiten zu setzen. Gibt es zu einer Seite keinen Duplicate Content, so verweist das Canonical-Tag auf die Seite, auf der es implementiert ist (als kanonische Seite). Das Canonical-Tag hätte somit folgenden Aufbau:
Besteht nun zu dieser Seite eine weitere Seite mit sehr ähnlichem oder identischem Content, so soll das Canonical auf die Ursprungsseite (kanonische Seite) verweisen. Auf dem Duplikat wird dementsprechend das gleiche Canonical-Tag wie auf der kanonischen Seite ausgewiesen. Das entspricht diesem Aufbau:
Seite (Duplikat): http://beispiel.de/unterseite1.html?parameter1¶meter2
Hierbei muss allerdings erwähnt werden, dass das Setzen dieses Tags nicht zwangsläufig die Indexierung der betreffenden Seiten verhindert. Sollen die Seiten oder Verzeichnisse aus dem Index ausgeschlossen werden, so muss mit dem Meta-Tag „robots“ gearbeitet werden.
Verwendung der Canonical Tags
Dieses Tag eignet sich hervorragend, um Duplikate von Anfang an zu vermeiden oder bestehende Duplikats-Problematiken in den Griff zu bekommen. Es findet vor allem bei den folgenden Punkten Anwendung:
Filterseiten
Ergebnisseiten der internen Suche
Kombinationen dieser Werkzeuge
Wie Du siehst, besitzen die vorgestellten Werkzeuge verschiedene Eigenschaften und Anwendungsbereiche. Es liegt nahe, eine Kombination aus diesen Werkzeugen vorzuschlagen, um sicherzustellen, dass die Seiten auch wirklich nicht im Index erscheinen. Warum das eine schlechte Idee ist, sollen die folgenden zwei Beispiele zeigen:
• Durch den Eintrag in der robots.txt wird dem Crawler/Spider verboten, ein Crawling der Seite durchzuführen. Aus diesem Grund können alle Tags auf der Seite nicht mehr greifen. Die Seite kann also weiterhin indexiert werden.
Canonical-Tag & Meta-Tag „noindex“
• Während der Canonical besagt, dass zwei Seiten identisch sind, besagt das „noindex“ Tag, dass die Seite nicht indexiert werden soll. Google muss sich dann folgende Frage stellen: Wenn diese Seite nicht indexiert werden soll, dann ihr Original auch nicht, oder?
Google ist eine Maschine und braucht für die Steuerung der Indexierung klare Anweisungen. Eine Kombination dieser Methoden ist daher nahezu immer ein Fehler!
Fazit
Mit den hier vorgestellten Methoden kannst Du einfach und effektiv Duplikate vermeiden und selbst entscheiden, welche Seiten durch Google in die Indexierung aufgenommen werden sollen. Überprüfe am besten selbst von Zeit zu Zeit mittels der Site-Abfrage, welche Seiten sich aktuell im Index befinden. Solltest Du weitere Informationen benötigen oder noch Fragen haben sind wir natürlich gerne für Euch da :- )
Teile diesen Beitrag
Über den Autor
Sophie Garban
Digital Marketing Managerin
Sophie war als Digital Marketing Managerin bei eMinded tätig und kümmerte sich vor allem um SEO & Content Marketing. In ihrer Freizeit sammelt sie fleißig Stempel in ihrem Reisepass, außerdem hat sie ein Faible für gutes Essen und spannende Bücher.
Du willst auf LinkedIn mit Deinem Content glänzen? In diesem Magazinartikel verraten wir Dir unsere Tipps und Tricks für Deinen perfekten LinkedIn-Beitrag. Jetzt lesen!
Penalty gibt es auch im Sport - denke an Eishockey oder an den Strafstoß beim Fußball. Doch was ist eine Google Penalty? Und wie entkommst Du ihr wieder, falls es Dich trotz aller Vorsicht mal erwischt haben sollte?
Wer mit Facebook Marketing seinen Marketing-Mix erweitern möchte,
sollte wissen, wie man dieses Instrument optimal für sich nutzen kann und was eine erfolgreiche Kampagne ausmacht. Wir zeigen Dir, wie du am besten vorgehst und geben dir wertvolle Tipps für Deine Kampagne an die Hand.